Enhancing Scan Performance with Redis Logical Databases

Redis is a powerful and versatile in-memory data store that is widely used for caching, session management, real-time analytics, and more. One of the key features of Redis is its support for logical databases, which allow users to partition their data within a single Redis instance. These logical databases provide isolation and separate namespaces for keys, enabling more efficient data management and organization. In this post, I will show how you can exploit logical databases to boost Redis query performance.
Logical Databases
Redis supports multiple logical databases, which are often referred to as "database numbers" or "DBs". Each logical database is isolated from others. Data stored in one database cannot be accessed directly from another database. This isolation provides a way to partition your data logically. Keys in Redis are unique within a database. Therefore, different databases provide separate namespaces for keys. You can use the same key in different databases without any conflict.
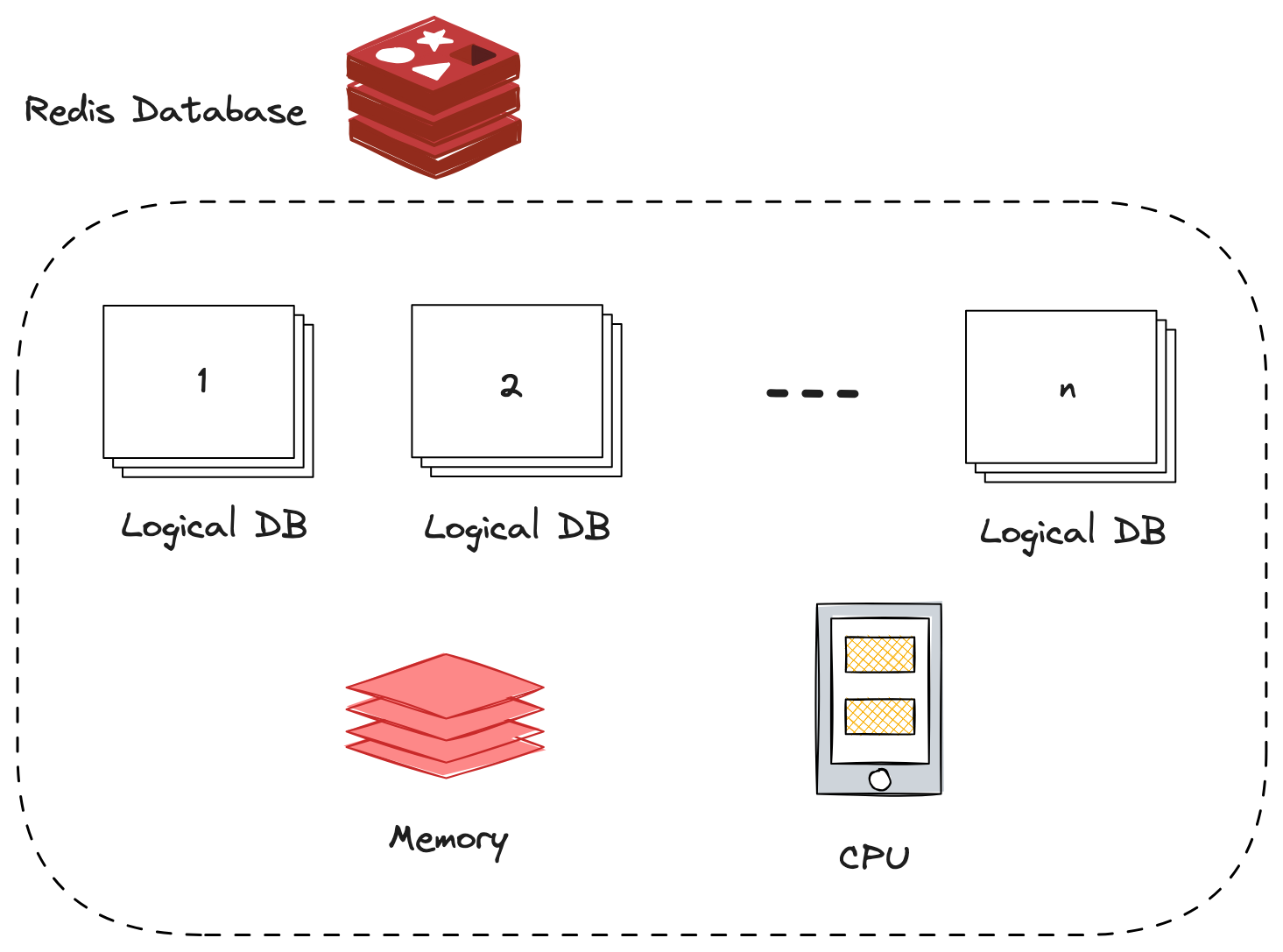
While logical databases provide isolation, they still share the same underlying physical resources (memory, CPU, etc.) within a single Redis instance. Therefore, heavy usage of one database can potentially impact the performance of others.
Scan performance
While Redis is not primarily designed for complex querying like traditional relational databases, there are scenarios where you might need to fetch a group of keys with the same prefix. This is a common requirement, especially in scenarios where keys are organized hierarchically or grouped by a common identifier.
Let's delve into a scenario where the performance of querying depends on the size of the database. Let's say you're using Redis for caching values of users who have visited your website recently, with a TTL (Time to Live) of 24 hours. These cached values are stored under the prefix user_id. Additionally, you have an Active Users cache for users currently using your service, with a prefix active_user_id and a TTL of 2 hours. Now, you have a process that periodically checks how many active users are present, and uses the Active Users cache. Here's how the performance could be affected by the size of the database.
As more users visit your website and their data is cached in Redis, the size of the database under the user_id prefix will grow. What could be surprising, scanning for active users could become slower even if the number of active users is stable. This is because the SCAN command traverses all keys in the database and applies a prefix pattern afterwards. See the following implementation. We have a simple function that populates the Redis database with random records with a given prefix.
import random
import redis
import string
def populate_db(host, port, db_number, key_prefix, n):
r = redis.Redis(host=host, port=port, db=db_number)
# Generate and load random data into Redis
for i in range(n):
suffix = ''.join(random.choices(string.ascii_letters, k=5))
key = f"{key_prefix}{suffix}"
value = ''.join(
random.choices(string.ascii_letters + string.digits, k=5),
)
r.set(key, value)
print("Data loaded into Redis.")
In Redis, the SCAN command is used for iterating over the keys in a database in a safe and efficient manner. The primary reason for using a cursor-based iteration approach with SCAN instead of fetching all keys (KEYS <prefix>) at once is to ensure that the operation does not block the Redis server or impact its performance negatively, especially in cases where the database is large.
import redis
def scan_redis_by_pattern(host, port, db_number, pattern):
r = redis.Redis(host=host, port=port, db=db_number)
num_keys = r.dbsize()
print(f"Number of keys DB={db_number}: {num_keys}")
cursor = 0
keys = []
while True:
cursor, partial_keys = r.scan(cursor, match=pattern)
keys.extend(partial_keys)
if cursor == 0:
break
return keys
Now we check the active_user_id query performance depending on the number of user_id records in the database.
host = 'localhost'
port = 6379
pattern = 'active_user_id:*'
db_number = 0
populate_db(host, port, db_number, "active_user_id:", 1)
for n in [10, 1000, 10000]:
populate_db(host, port, db_number, "user_id:", n)
start = time.time()
keys = scan_redis_by_pattern(host, port, db_number, pattern)
print(
f"Keys: {keys}, Duration: {time.time() - start}s",
)
We got the following results:
Data loaded into Redis.
Data loaded into Redis.
Number of keys DB=0: 11
Keys: [b'active_user_id:aTtsr'], Duration: 0.004511117935180664s
-----------------------------------------------------------------------
Data loaded into Redis.
Number of keys DB=0: 1011
Keys: [b'active_user_id:aTtsr'], Duration: 0.051651954650878906s
-----------------------------------------------------------------------
Data loaded into Redis.
Number of keys DB=0: 100999
Keys: [b'active_user_id:aTtsr'], Duration: 4.748287916183472s
As the number of user_id keys in the database increases, the time taken to perform the active_user_id query also increases proportionally (from several milliseconds to a few seconds). This highlights the importance of considering database size and performance implications when designing and managing a Redis database.
If we keep active_user_id and user_id records in separate logical databases, the elevated volume of user_id key will not impact active_user_id scanning.
Data loaded into Redis.
Number of keys DB=0: 1000990
Number of keys DB=1: 1
Keys: [b'active_user_id:DsHfN'], Duration: 0.003325939178466797s
As you have seen, separating data into logical databases can be a simple yet effective design strategy to improve performance in Redis.
Conclusion
Redis logical databases offer a powerful mechanism for organizing and managing data within a single Redis instance. By partitioning data into separate logical databases, users can achieve better isolation and more efficient data access. However, it's essential to be mindful of the potential performance impacts due to shared memory and CPU utilization.
The code snippets used in this post can be found here.




